
Lecture 2 | Image Classification
Lecture 2 | Image Classification
Image Classification (이미지 분류)
Image classification concept
이미지 분류는 컴퓨터 비전에서 중요한 과업이다.

컴퓨터 비전에서 이미지분류 과정은 다음과 같다.
- 이미지를 입력 데이터로 넣는다.
- 카테고리가 담긴 것들 중 하나를 골라 낸다.
The Problem
하지만 이러한 과정에는 문제점들이 있다.

위와 같이 컴퓨터는 사람과 달리 이미지를 일련의 숫자들로 인식한다.
Challenges
이미지 분류에서는 위의 문제점말고도 많은 문제점들이있다.
- Viewpoint variation (객체를 보는 각도)
- Illumination (조명)
- Deformation (객체의 형태 변환)
- Occlusion (객체가 가려짐)
- BackGround Clutter (객체와 배경간의 혼란)
- Intraclass Variation (객체간 변형)
예시사진)






Image classifier

이미지 분류기를 만드는 데 명확한 알고리즘은 존재하지 않는다.
따라서 우리는 몇 가지의 시도를 해볼 수 있다.
첫 번째 시도는 이미지의 edge와 corner를 찾고 그것의 따른 명시적인 룰을 만들어 이미지 분류를 할 수 있는 이미지 분류기를 만드는 것이다.
하지만 이와 같은 분류기는 문제점이 있다. 첫 번째로는 알고리즘이 강인하지 않는다는 것이고 두 번째로는 확장성이 없다는 것이다.
두 번째 시도는 Data-Driven Approach를 사용하는 것이다.
Data-Driven Approach 과정은 다음과 같다.
- Collect a dataset of images and label
- Use Machine Learning to train a classifier
- Evaluate the classifier on new images

Nearest Neighbor
Nearest Neighbor는 두 번째 시도인 Data-Driven Approach를 사용한 이미지 분류기법이다.
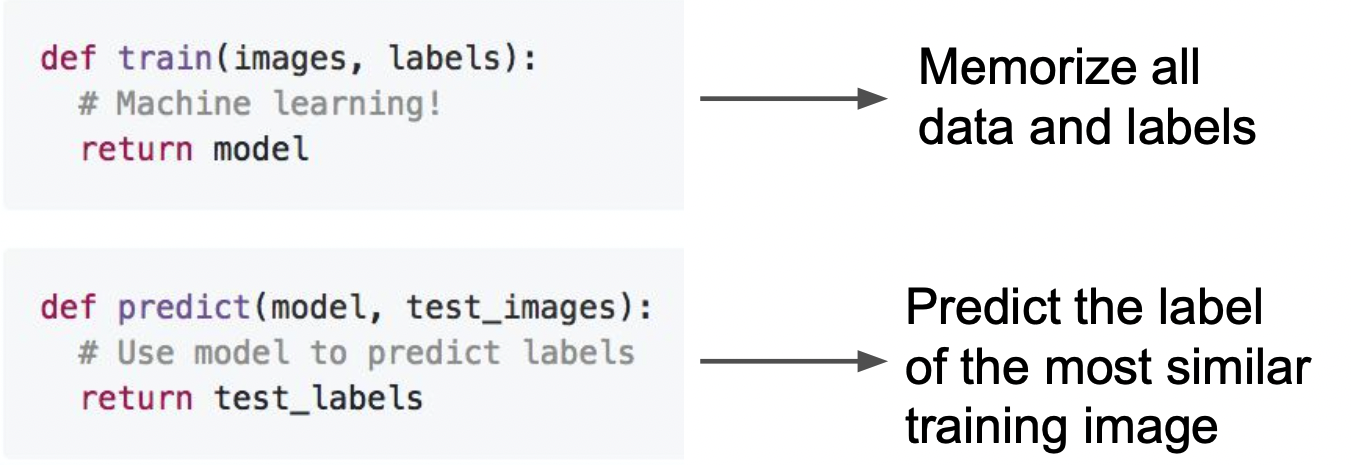
train(학습)과정
- 단순히 모든 데이터(입력)와 라벨(정답)을 저장한다.
test(예측)과정
- 각각의 test_image마다 가까운 train_image를 찾는다.
- 찾은 가까운 이미지로 라벨(정답)을 예측한다.
Dataset: CIFAR10
dataset으로는 CIFAR10을 사용하였다.

Nearest Neighbor의 Distance Metric은 L1 distance를 사용한다. L1 distance는 다음과 같은 수식과 과정을 갖는다.

Nearest Neighbor의 코드 구현

위 코드로 N개의 이미지를 학습 및 예측을 한다면 시간복잡도는 다음과 같다.
- Train → O(1)
- Predict → O(N)
이렇게 Train 속도가 Predict보다 빠른 모델은 좋지않다. 즉 Train은 조금 느리지만 Predict는 빨라야한다. 그 이유는 학습시킨 모델은 모바일, 웹, 특정분야 등.. 많은 곳에서 쓰이고 predict가 느리면 사용하기에 시간이 많이 들기 때문이다.
K-Nearest Neighbor
K-Nearest Neighbor은 nearest neigbor로부터 라벨을 단순히 카피하는 것이 아니라 K개의 주변의 점들로부터 투표를 통해 라벨을 선정하는 방식이다.
K-Nearest Neighbor의 Distance Metric은 두 가지가 있다.
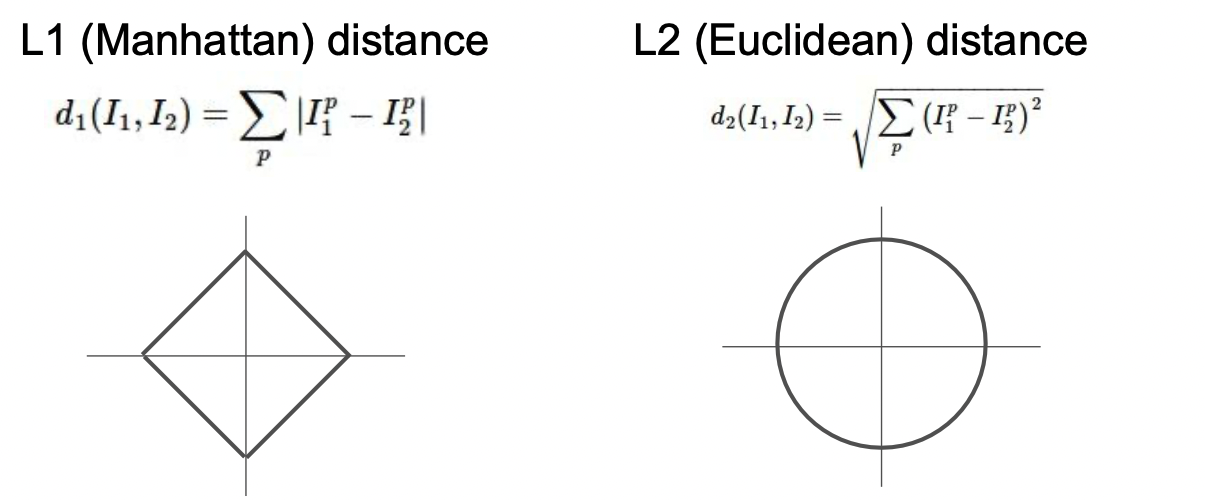
하나는 기존에 사용하던 L1 distance를 활용하는 것이고 다른 하나는 L2 distance를 활용하는 것이다.
L1 distance는 특징벡터가 개별적인 의미를 가지고 있으면 사용하고 L2 distance는 일반적인 벡터에서 사용한다. 두 개의 metric을 사용한 K-Nearest Neighbor는 다음과 같다.
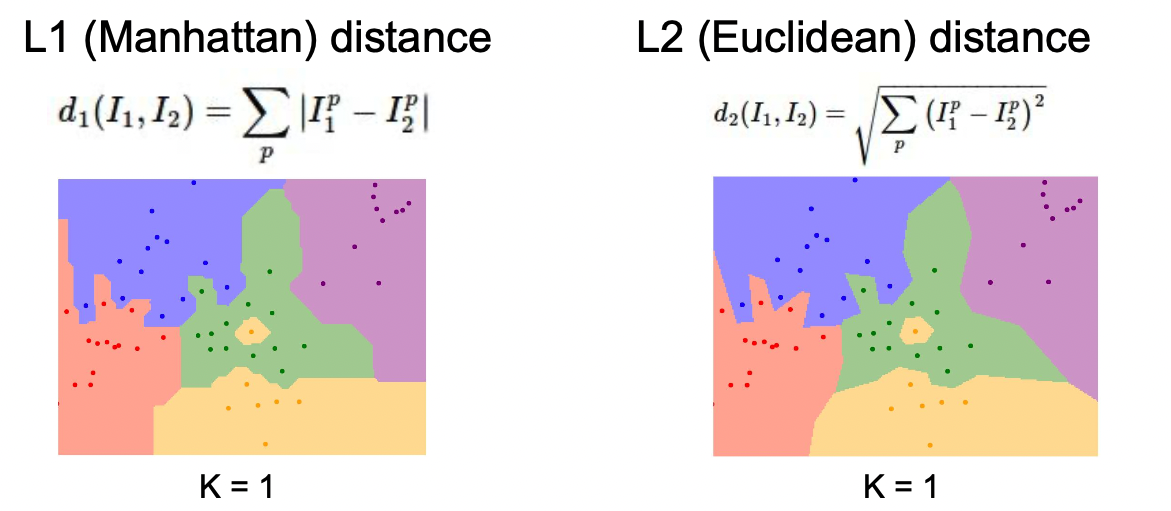
Hyperparameters
K-Nearest Neighbor를 사용할 때 우리는 직접 k값과 어떤 distance metirc을 사용할 것인지 정해야한다. 이렇게 사람이 직접 정하는 변수를 hyperparameter라고 한다.
Hyperparameter를 정하는 방법은 아래와 같다.

- Idea 1: 전체 dataset에 대해 적절한 하이퍼파라미터 찾기
- Idea 2: 전체 dataset을 train data와 test data으로 분류 후 test data에 적절한 하이퍼파라미터 찾기
- Idea 3: 전체 dataset을 train data, validation data, test data로 분루 휴 validation data에 적절한 하이퍼파라미터르 찾은 후 test data에서 평가하기
Idea 1과 같은 경우는 k=1일때는 항상 하이퍼파라미터가 무엇이든지 잘 동작하기 때문에 좋지않고 Idea 2와 같은 경우는 test에 적합한 하이퍼파라미터를 찾았기 때문에 새로운 데이터에서 잘 수행될지 모른다. 따라서 Idea 3과같은 방법이 적절한 하이퍼파라미터 찾는 방법이다.
또 Idea 3에서 확장된 버전이 Idea 4(Cross-Validation)인데 이것은 전체 dataset을 여러개로 분할하고 test data를 제외한 나머지 조각을 번갈아 가면서 validation data로 활용하는 것이다. 수행 에시는 아래와 같다.

K-Nearest Neighbor의 단점
지금까지 배운 K-Nearest Neighbor는 이미지 분류를 할 떄 사용하지 말아야 한다. 그 이유는 test time이 굉장히 느리고 다른 이미지여도 distance metric은 같게 나올 수 있기 때문이다.
distance metric이 같은 예시

또한 차원이 증가할 수록 많은 디스크가 소모된다.

Linear Classification

Linear Classifiers는 각각의 블럭(Neural Network)을 차곡차곡 쌓아 만든 그림으로 표현 할 수있다.
이러한 Linear Classifiers에 이미지를 적용하면 다음과 같다.

분류기를 f(x)라는 함수로 생각하고 하나의 이미지를 10개의 class score를 뽑아낸는 과정을 생각해보자.

한 장의 이미지는 f(x,W)라는 함수를 거쳐 최종적으로 10개의 class scores로 변환된다.
함수 f(x,W)에서 W는 weight(가중치)를 의미하고 b는 편향을 의미한다.
f(x,W)를 구체적으로 살펴보면 다음과 같다.

이미지의 각각의 픽셀은 W값을 내적한 후 편향값을 더해 class별 score값을 도출한다.
이것을 CIFAR-10데이터에 적용하면 아래 그림과 같다.

Syllabus
Youtube
'Deep Learning > cs231n' 카테고리의 다른 글
| Lecture 6 | Training Neural Networks I (0) | 2022.02.05 |
|---|---|
| Lecture 5 | Convolutional Neural Networks (0) | 2022.01.28 |
| Lecture 4 | Introduction to Neural Networks (0) | 2022.01.21 |
| Lecture 3 | Loss Functions and Optimization (0) | 2022.01.15 |
| Lecture 0 | CS321n (0) | 2022.01.14 |








