
Exploration 09
2022. 2. 3. 11:59
의료영상에 대해
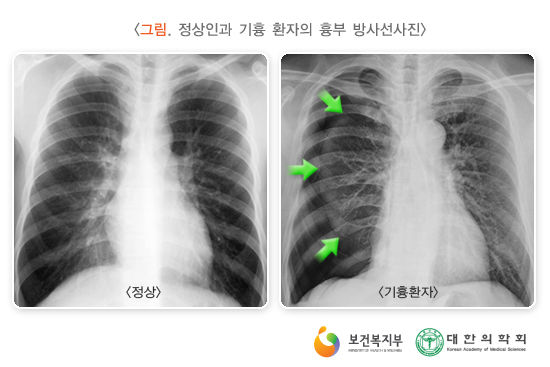
의료 영상 종류
- X-RAY: 전자를 물체에 충돌시킬 때 발생하는 투과혁이 강한 복사선(전자기파), X-RAY는 방사선의 일종으로 지방, 근육, 천, 종이같이 밀도가 낮은 것은 수월하게 통과하지만, 밀도가 높은 뼈, 금속 같은 물질은 잘 통과하지 못한다.
- CT: Computed Tomography의 줄임말로, 환자를 중심으로 X-RAY를 빠르게 회전하여 3D 이미지를 만들어내는 영상, 환자의 3 차원 이미지를 형성하여 기본 구조는 물론 가능한 종양 또는 이상을 쉽게 식별하고 위치를 파악할 수 있다.
- MRI: Magnetic Resonance Imaging(자기 공명 영상)의 줄임말로 신체의 해부학적 과정과 생리적 과정을 보기 위해 사용하는 의료 영상 기술, MRI 스캐너는 강한 자기장를 사용하여 신체 기관의 이미지를 생성한다. MRI는 CT, X-RAY와 다르게 방사선을 사용하지 않아서 방사선의 위험성에서는 보다 안전하다.
X-RAY 이미지
의료영상 자세 분류
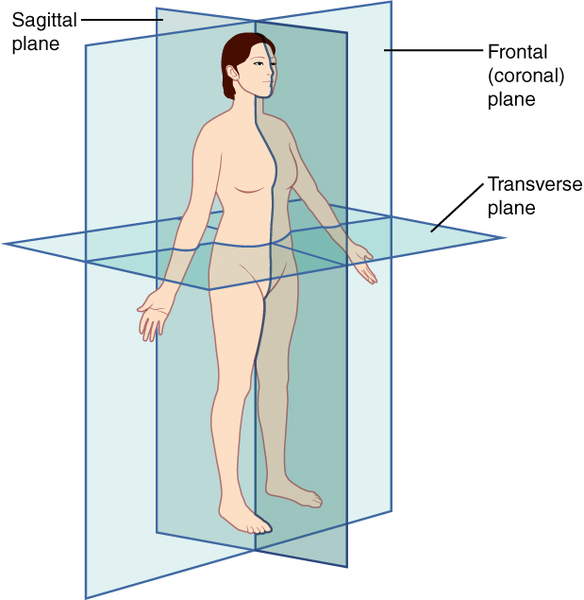
- Sagittal plane : 시상면. 사람을 왼쪽과 오른쪽을 나누는 면.
- Coronal plane : 관상면. 인체를 앞뒤로 나누는 면.
- Transverse plane : 횡단면(수평면). 인체를 상하로 나누는 면.
X-RAY 특성
- X-RAY는 전자기파가 몸을 통과한 결과흫 이미지화 시킨 것이기 때문에 흑백 명암으로 나오게 된다.

- 뼈: 하얀색
- 근욱 및 지방: 연한 회색
- 공기: 검은 색

- 갈비뼈: 하얀 색
- 폐: 검은 색
- 어깨 쪽의 지방 및 근육: 연한 회색
폐렴 구별법

폐렴의 구별법은 X-RAY 사진상 다양한 양상의 음영(폐 부위에 희미한 그림자)증가를 관찰하는 것이다.
하지만 실제로 영상을 보면 희미한 경우가 많이 있어 저제 실제로 폐렴으로 인한 것인지 아니면 다른 이유 때문인지 파악하기 어렵다.
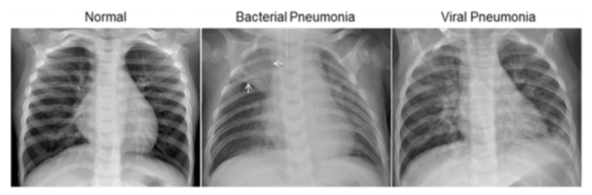
- Nomal: 비정상적인 음영 영역이 없는 깨끗한 폐를 보여준다.
- Bacterial Pneumonia(세균성 폐렴): 일반적으로 오른쪽 상부 엽에 나타나고
- viral Pneumonia(바이러스성 폐렴): 양족 폐에서보다 확산된 interstitial(조직 사이에 있는)패턴으로 나타난다.
데이터셋 준비
kaggle의 Chest X-Ray Images
- 5856개의 X-ray 이미지 (JPEG)
- 2개의 class(폐렴, 정상)
Set-up
import os, re
import random, math
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings(action='ignore')# 데이터 로드할 때 빠르게 로드할 수 있도록하는 설정 변수
AUTOTUNE = tf.data.experimental.AUTOTUNE
# X-RAY 이미지 사이즈 변수
IMAGE_SIZE = [180, 180]
# 데이터 경로 변수
ROOT_PATH = os.path.join(os.getenv('HOME'), 'aiffel')
TRAIN_PATH = ROOT_PATH + '/chest_xray/data/train/*/*' # *은 모든 디렉토리와 파일을 의미합니다.
VAL_PATH = ROOT_PATH + '/chest_xray/data/val/*/*'
TEST_PATH = ROOT_PATH + '/chest_xray/data/test/*/*'
# 프로젝트를 진행할 때 아래 두 변수를 변경해보세요
BATCH_SIZE = 16
EPOCHS = 25
print(ROOT_PATH)데이터 가져오기
train_filenames = tf.io.gfile.glob(TRAIN_PATH)
test_filenames = tf.io.gfile.glob(TEST_PATH)
val_filenames = tf.io.gfile.glob(VAL_PATH)
print(len(train_filenames))
print(len(test_filenames))
print(len(val_filenames))
'''
5216
624
16
'''- train: 5216개 (89%)
- test: 624개 (10.7%)
- val: 16개 (0.3%)
train, val 데이터를 합치고 다시 분할
# train 데이터와 validation 데이터를 모두 filenames에 담습니다
filenames = tf.io.gfile.glob(TRAIN_PATH)
filenames.extend(tf.io.gfile.glob(VAL_PATH))
# 모아진 filenames를 8:2로 나눕니다
train_size = math.floor(len(filenames)*0.8)
random.seed(8)
random.shuffle(filenames)
train_filenames = filenames[:train_size]
val_filenames = filenames[train_size:]
print(len(train_filenames))
print(len(val_filenames))
'''
4185
1047
'''- train: 4185개
- test: 624개
- val: 1047개
데이터 불균형 확인
파일 경로 이름으로 확인
print(f'Normal image path\n{filenames[0]}')
print(f'Pneumonia image path\n{filenames[2000]}')
'''
Normal image path
/aiffel/aiffel/chest_xray/data/train/NORMAL/NORMAL2-IM-1317-0001.jpeg
Pneumonia image path
/aiffel/aiffel/chest_xray/data/train/PNEUMONIA/person299_bacteria_1418.jpeg
'''
COUNT_NORMAL = len([filename for filename in train_filenames if "NORMAL" in filename])
print(f"Normal images count in training set: {COUNT_NORMAL}")
COUNT_PNEUMONIA = len([filename for filename in train_filenames if "PNEUMONIA" in filename])
print(f"Pneumonia images count in training set: {COUNT_PNEUMONIA}")
'''
Normal images count in training set: 1072
Pneumonia images count in training set: 3113
'''정상보다 폐렴의 이미지 수가 3배 더 많다.
우리가 사용할 CNN모델의 경우 데이터가 클래스별 balance가 좋을수록 training을 잘 한다. 따라서 데이터가 클래스 imbalance한 것은 차후에 조정이 필요하다.
인스터스 tf.data
train_list_ds = tf.data.Dataset.from_tensor_slices(train_filenames)
val_list_ds = tf.data.Dataset.from_tensor_slices(val_filenames)train, test 개수 확인
TRAIN_IMG_COUNT = tf.data.experimental.cardinality(train_list_ds).numpy()
print(f"Training images count: {TRAIN_IMG_COUNT}")
VAL_IMG_COUNT = tf.data.experimental.cardinality(val_list_ds).numpy()
print(f"Validating images count: {VAL_IMG_COUNT}")파일 경로로 라벨 데이터 만들기
# 파일 경로의 끝에서 두번째 부분을 확인하면 양성과 음성을 구분할 수 있습니다
def get_label(file_path):
parts = tf.strings.split(file_path, os.path.sep)
return parts[-2] == "PNEUMONIA" # 폐렴이면 양성(True), 노말이면 음성(False)
# 이미지 파일의 경로를 입력하면 이미지와 라벨을 읽어옵니다.
def process_path(file_path):
label = get_label(file_path) # 라벨 검출
img = tf.io.read_file(file_path) # 이미지 읽기
img = decode_img(img) # 이미지를 알맞은 형식으로 수정
return img, label이미지 사이즈 조절
# 이미지를 알맞은 형식으로 바꿉니다.
def decode_img(img):
img = tf.image.decode_jpeg(img, channels=3) # 이미지를 uint8 tensor로 수정
img = tf.image.convert_image_dtype(img, tf.float32) # float32 타입으로 수정
img = tf.image.resize(img, IMAGE_SIZE) # 이미지 사이즈를 IMAGE_SIZE로 수정
return imgtrain, validation set 만들기
# num_parallel_calls파라미터에 위에서 할당한 AUTOTUNE변수를 이용하면 더욱 빠르게 데이터를 처리함
train_ds = train_list_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_list_ds.map(process_path, num_parallel_calls=AUTOTUNE)이미지 사이즈, 라벨 확인
for image, label in train_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
'''
Image shape: (180, 180, 3)
Label: False
'''test set 만들기
test_list_ds = tf.data.Dataset.list_files(TEST_PATH)
TEST_IMAGE_COUNT = tf.data.experimental.cardinality(test_list_ds).numpy()
test_ds = test_list_ds.map(process_path, num_parallel_calls=AUTOTUNE)
test_ds = test_ds.batch(BATCH_SIZE)
print(TEST_IMAGE_COUNT)
'''
624
'''def prepare_for_training(ds, shuffle_buffer_size=1000):
ds = ds.shuffle(buffer_size=shuffle_buffer_size)
ds = ds.repeat()
ds = ds.batch(BATCH_SIZE)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = prepare_for_training(train_ds)
val_ds = prepare_for_training(val_ds)- shiffle(): 고정크기 버퍼를 유지하고 해당 버퍼에서 무작위로 균일하게 다음요소를 선택
- repeat(): epoch를 진행하면서 여러 번 데이터셋을 불러오게 되는데, 이때 repeat()를 사용한 데이터 셋의 경우 여러 번 데이터셋을 사용할 수 있게 해준다.
- batch(): 자신이 정한 배치사이즈만큼 배치로 주어진다.
- prefetch(): 첫 번째 데이터를 GPU에서 학습하는 동안 두 번째 데이터를 CPU에서 준비할 수 있어 리소스의 유휴 상태를 줄일 수 있다.
데이터 시각화
# 이미지 배치를 입력하면 여러장의 이미지를 보여줍니다.
def show_batch(image_batch, label_batch):
plt.figure(figsize=(10,10))
for n in range(BATCH_SIZE):
ax = plt.subplot(4,math.ceil(BATCH_SIZE/4),n+1)
plt.imshow(image_batch[n])
if label_batch[n]:
plt.title("PNEUMONIA")
else:
plt.title("NORMAL")
plt.axis("off")
image_batch, label_batch = next(iter(train_ds))
show_batch(image_batch.numpy(), label_batch.numpy())
CNN 모델링
def conv_block(filters):
block = tf.keras.Sequential([
tf.keras.layers.SeparableConv2D(filters, 3, activation='relu', padding='same'),
tf.keras.layers.SeparableConv2D(filters, 3, activation='relu', padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.MaxPool2D()
])
return blockdef dense_block(units, dropout_rate):
block = tf.keras.Sequential([
tf.keras.layers.Dense(units, activation='relu'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(dropout_rate)
])
return block- Batch Normalization: variance shift를 억제
- Dropout: variance shift를 유발
def build_model():
model = tf.keras.Sequential([
tf.keras.Input(shape=(IMAGE_SIZE[0], IMAGE_SIZE[1], 3)),
tf.keras.layers.Conv2D(16, 3, activation='relu', padding='same'),
tf.keras.layers.Conv2D(16, 3, activation='relu', padding='same'),
tf.keras.layers.MaxPool2D(),
conv_block(32),
conv_block(64),
conv_block(128),
tf.keras.layers.Dropout(0.2),
conv_block(256),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Flatten(),
dense_block(512, 0.7),
dense_block(128, 0.5),
dense_block(64, 0.3),
tf.keras.layers.Dense(1, activation='sigmoid')
])
return model데이터 imbalance 처리
weight balancing 사용
Weight balancing이란?
training set의 각 데이터에서 loss를 계산할 때 특정 클래스의 데이터에 더 큰 loss 값을 갖도록 가중치를 부여하는 방법
weight_for_0 = (1 / COUNT_NORMAL)*(TRAIN_IMG_COUNT)/2.0
weight_for_1 = (1 / COUNT_PNEUMONIA)*(TRAIN_IMG_COUNT)/2.0
class_weight = {0: weight_for_0, 1: weight_for_1}
print('Weight for NORMAL: {:.2f}'.format(weight_for_0))
print('Weight for PNEUMONIA: {:.2f}'.format(weight_for_1))모델 훈련
- device: GPU
- loss: binary_cross entropy
- optimizer: adam
- metrics: accurancy, precision, recall
with tf.device('/GPU:0'):
model = build_model()
METRICS = [
'accuracy',
tf.keras.metrics.Precision(name='precision'),
tf.keras.metrics.Recall(name='recall')
]
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=METRICS
)with tf.device('/GPU:0'):
history = model.fit(
train_ds,
steps_per_epoch=TRAIN_IMG_COUNT // BATCH_SIZE,
epochs=EPOCHS,
validation_data=val_ds,
validation_steps=VAL_IMG_COUNT // BATCH_SIZE,
class_weight=class_weight,
)
'''
Epoch 25/25
261/261 [==============================] - 48s 185ms/step - loss: 0.0655 - accuracy: 0.9761 - precision: 0.9954 - recall: 0.9722 - val_loss: 0.1462 - val_accuracy: 0.9519 - val_precision: 0.9451 - val_recall: 0.9921
'''결과 확인
fig, ax = plt.subplots(1, 4, figsize=(20, 3))
ax = ax.ravel()
for i, met in enumerate(['precision', 'recall', 'accuracy', 'loss']):
ax[i].plot(history.history[met])
ax[i].plot(history.history['val_' + met])
ax[i].set_title('Model {}'.format(met))
ax[i].set_xlabel('epochs')
ax[i].set_ylabel(met)
ax[i].legend(['train', 'val'])
모델 평가
loss, accuracy, precision, recall = model.evaluate(test_ds)
print(f'Loss: {loss},\nAccuracy: {accuracy},\nPrecision: {precision},\nRecall: {recall}')
'''
39/39 [==============================] - 5s 115ms/step - loss: 2.1950 - accuracy: 0.7083 - precision: 0.6831 - recall: 0.9949
Loss: 2.195019006729126,
Accuracy: 0.7083333134651184,
Precision: 0.6830986142158508,
Recall: 0.9948717951774597
''''AIFFEL > exploration' 카테고리의 다른 글
| Exploration 11 (0) | 2022.02.10 |
|---|---|
| Exploration 10 (0) | 2022.02.08 |
| Exploration 08 (0) | 2022.01.27 |
| Exploration 07 (0) | 2022.01.25 |
| Exploration 06 (0) | 2022.01.20 |








