
Exploration 07
셸로우 포커스(shallow focus)
배경을 흐리게 하는 기술, 얕은 피사계 심도(shallow depth of field)라고도 불림
사진을 준비하자
하나의 카메라로 셸로우 포커스를 만드는 방법

- 배경이 있는 셀카를 촬영합니다. (배경과 사암의 거리가 약간 멀리 있으면 좋습니다.)
- 시맨틱 세그멘테이션(Semantic segmentation)으로 피사체와 배경을 분리합니다.
- 블러링(bluring) 기술로 배경을 흐리게 합니다.
- 피사체를 배경의 원래 위치에 합성합니다.
import os
import urllib # 웝에서 데이터를 다운로드할 때 사용
import cv2 # 이미지를 처리할 때 사용
import numpy as np
from pixellib.semantic import semantic_segmentation # 시맨틱 세그멘테이션을 할 때 사용
from matplotlib import pyplot as plt# 본인이 선택한 이미지의 경로에 맞게 바꿔 주세요.
img_path = os.getenv('HOME')+'/aiffel/human_segmentation/images/img.jpg'
img_orig = cv2.imread(img_path)
print(img_orig.shape)
plt.imshow(cv2.cvtColor(img_orig, cv2.COLOR_BGR2RGB))
plt.show()세그멘테이션으로 사람 분리하기
세그멘테이션(Segment)이란?
이미지에서 픽셀 단위로 관심 객체를 추출하는 방법을 이미지 세그멘테이션(images segmentation)이라고 한다.
이미지 세그멘테이션은 모든 픽셀에 라벨을 할당하고 같은 라벨은 공통적인 특징을 가진다고 가정한다. 이때 피셀이 비슷하게 생겼다는 사실은 인식하지만 우리가 아는 것처럼 실제 물체 단위로 인식하지 않을 수 있다.
시맨틱 세그멘테이션(semantic segmentation)이란?
세그멘테이션 중에서도 특리 우리가 인식하는 세계처럼 물리적 의미 단위로 인식하는 세그멘테이션을 시맨틱 세그멘테이션이라고 한다.
쉽게 설명하면 이미지에서 픽셀을 사람, 자동차, 비행기 등의 물리적단위로 분류(classification)라는 방법이라고 이해하면된다.
인스턴스 세그멘테이션(Instance segmentation)이란?
인스턴스 세그멘테이션은 사람 개개인별로 다른 라벨을 가지게 한다. 여러 사람이 한 이미지에 등장할 때 각 객체를 분할해서 인식하자는 것이 목표이다.

시맨틱 세그멘테이션 다뤄보기
세그멘테이션 모델: FCN, SegNet, U-Net, DeepLab...등등
DeepLab

DeepLab은 많은 Sematic segmentation 모델중 가장 성능이 좋은 모델이다.
Atrous Convolution

Atrous convolution은 기존 convolution과 다르게 필테내부에 빈 공간을 둔 채로 작동한다.
Atrous convolution의 이점
- 기존 convolution과 동일한 양의 차라미터와 계산량을 유지하면서도, field of view를 크게 가져갈 수 있다.
semantic segmentation에서 높은 성늘으 내기 위해서는 convolutional neural network의 마지막에 존재하는 한 팍셀이 입력삽에서 어느 크기의 영역을 커버할 수 있는지를 결정하는 erceptive field크기가 중요하게 자용한다. Atrous convolution을 활용하면 파라미터 수를 늘리지 않으면서도 receptive field를 크게 키울 수 있다.
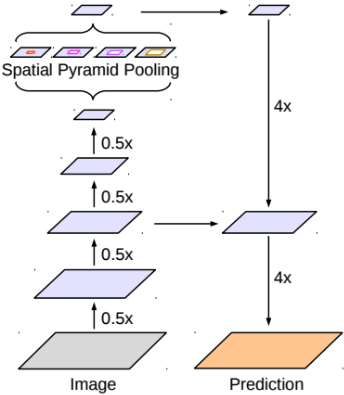
Spatial Pyramid Pooling
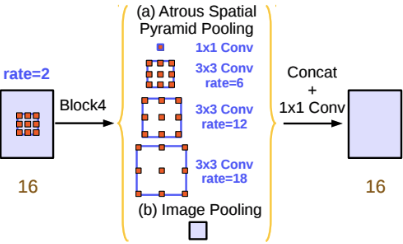
Semantic segmentaion의 성능을 높이기 위한 방법 중 하나로, spatial pyramid pooling 기법이 자주 활용되고 있는 추세이다. DeepLab V2에서는 feature map으로부터 여러 개의 rate가 다른 atrous convolution을 병렬로 적용한 뒤, 이를 다시 합쳐주는 atrous spatial pyramid pooling (ASPP) 기법을 활용할 것을 제안한다.
Encoder-Decoder
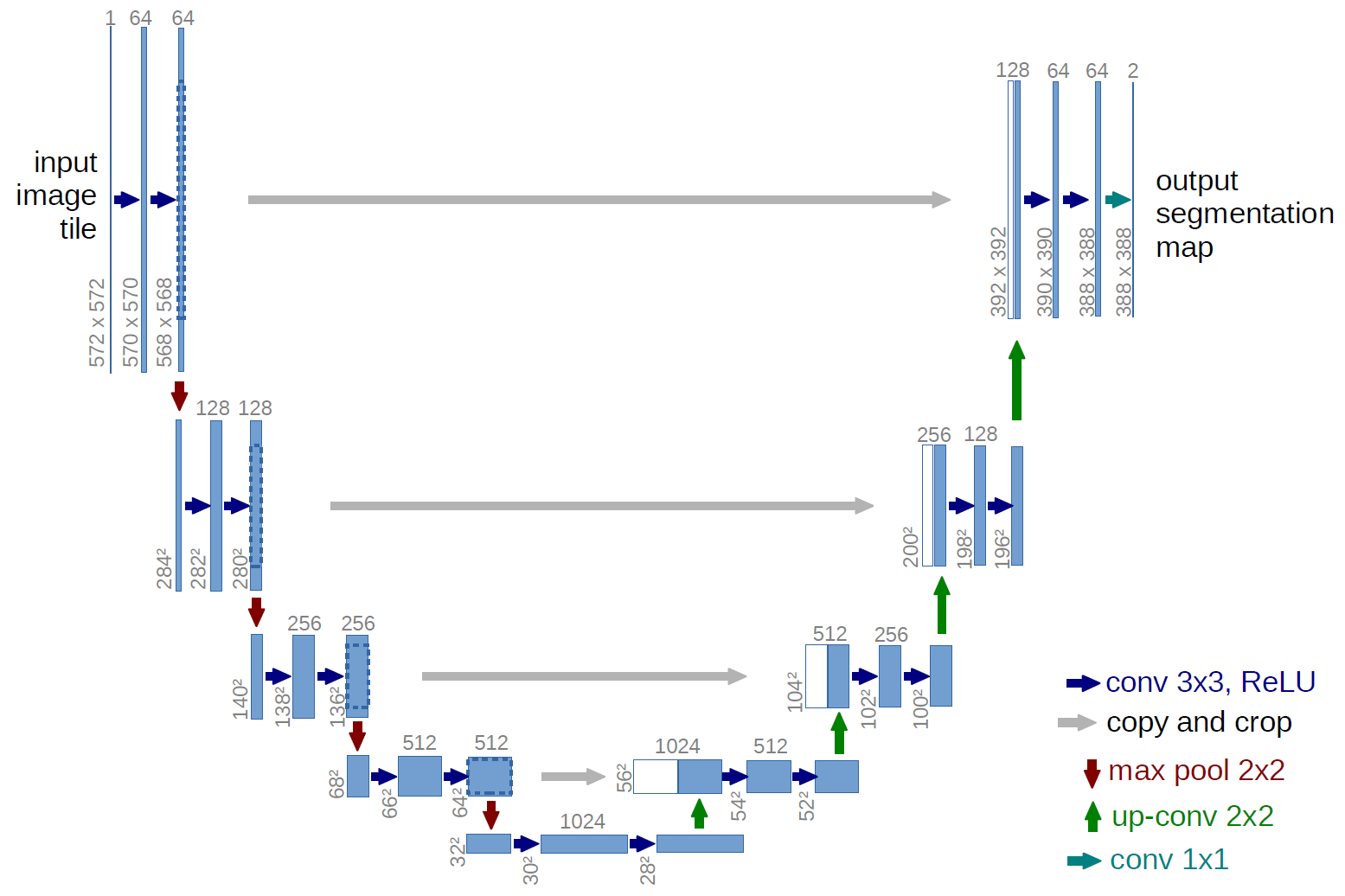
U-Net이라 불리는 encoder-decoder 구조는 정교한 픽셀 단위의 segmentation이 요구되는 biomedical image segmentation task의 핵심 요소로 자리잡고 있다.왼쪽의 encoder 부분에서는 점진적으로 spatial dimension을 줄여가면서 고차원의 semantic 정보를 convolution filter가 추출해낼 수 있게 된다. 이후 오른쪽의 decoder 부분에서는 encoder에서 spatial dimension 축소로 인해 손실된 spatial 정보를 점진적으로 복원하여 보다 정교한 boundary segmentation을 완성하게 된다.
U-Net이 여타 encoder-decoder 구조와 다른 점은, 위 그림에서 가운데 놓인 회색 선이다. Spatial 정보를 복원하는 과정에서 이전 encoder feature map 중 동일한 크기를 지닌 feature map을 가져 와 prior로 활용함으로써 더 정확한 boundary segmentation이 가능하게 만든다.
Depthwise Separable Convolution

Convolution 연산에서 channel 축을 filter가 한 번에 연산하는 대신에, 위 그림과 같이 입력 영상의 channel 축을 모두 분리시킨 뒤, channel 축 길이를 항상 1로 가지는 여러 개의 convolution 필터로 대체시킨 연산을 depthwise convolution이라고 합니다.

이제, 위의 depthwise convolution으로 나온 결과에 대해, 1×1×C 크기의 convolution filter를 적용한 것을 depthwise separable convolution 이라 합니다. 이처럼 복잡한 연산을 수행하는 이유는 기존 convolution과 유사한 성능을 보이면서도 사용되는 파라미터 수와 연산량을 획기적으로 줄일 수 있기 때문입니다.
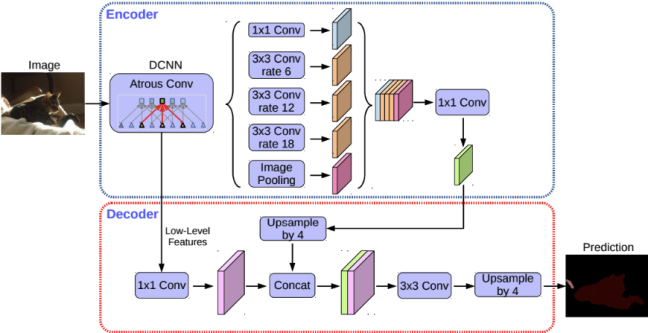
DeepLab V3+
- Encoder: ResNet with atrous convolution → Xception (Inception with separable convolution)
- ASPP → ASSPP (Atrous Separable Spatial Pyramid Pooling)
- Decoder: Bilinear upsampling → Simplified U-Net style decoder
# 모델 준비
# 저장할 파일 이름을 결정합니다
model_dir = os.getenv('HOME')+'/aiffel/human_segmentation/models'
model_file = os.path.join(model_dir, 'deeplabv3_xception_tf_dim_ordering_tf_kernels.h5')
# PixelLib가 제공하는 모델의 url입니다
model_url = 'https://github.com/ayoolaolafenwa/PixelLib/releases/download/1.1/deeplabv3_xception_tf_dim_ordering_tf_kernels.h5'
# 다운로드를 시작합니다
urllib.request.urlretrieve(model_url, model_file)
# 모델 생성
model = semantic_segmentation()
model.load_pascalvoc_model(model_file)
# 모델에 이미지 입력
segvalues, output = model.segmentAsPascalvoc(img_path)# PASCAL VOC데이터의 라벨 종류 확인
LABEL_NAMES = [
'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike',
'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv'
]
len(LABEL_NAMES)
'''
LABEL_NAMES = [
'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike',
'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv'
]
len(LABEL_NAMES)
'''# output
plt.imshow(output)
plt.show()
segvalues
'''
{'class_ids': array([ 0, 15]),
'masks': array([[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., True, True, True],
[False, False, False, ..., True, True, True],
[False, False, False, ..., True, True, True]])}
'''
for class_id in segvalues['class_ids']:
print(LABEL_NAMES[class_id])
'''
background
person
'''결과
- output에는 세그멘테이션이 된 결과가 각각 다른 색상으로 담겨있다.
- segvalues에는 class_ids와 masks가 있다.
- class_ids를 통해 어떤 물체가 담겨있는지 알 수 있다.
# 아래 코드를 이해하지 않아도 좋습니다
# PixelLib에서 그대로 가져온 코드입니다
# 주목해야 할 것은 생상 코드 결과물이예요!
colormap = np.zeros((256, 3), dtype = int)
ind = np.arange(256, dtype=int)
for shift in reversed(range(8)):
for channel in range(3):
colormap[:, channel] |= ((ind >> channel) & 1) << shift
ind >>= 3
colormap[:20]
'''
array([[ 0, 0, 0],
[128, 0, 0],
[ 0, 128, 0],
[128, 128, 0],
[ 0, 0, 128],
[128, 0, 128],
[ 0, 128, 128],
[128, 128, 128],
[ 64, 0, 0],
[192, 0, 0],
[ 64, 128, 0],
[192, 128, 0],
[ 64, 0, 128],
[192, 0, 128],
[ 64, 128, 128],
[192, 128, 128],
[ 0, 64, 0],
[128, 64, 0],
[ 0, 192, 0],
[128, 192, 0]])
'''# 마스크 만들기
colormap[15]
'''
array([192, 128, 128])
'''
seg_color = (128,128,192)
# output의 픽셀 별로 색상이 seg_color와 같다면 1(True), 다르다면 0(False)이 됩니다
seg_map = np.all(output==seg_color, axis=-1)
print(seg_map.shape)
plt.imshow(seg_map, cmap='gray')
plt.show()
# 원본 이미지와 곂쳐보기
img_show = img_orig.copy()
# True과 False인 값을 각각 255과 0으로 바꿔줍니다
img_mask = seg_map.astype(np.uint8) * 255
# 255와 0을 적당한 색상으로 바꿔봅니다
color_mask = cv2.applyColorMap(img_mask, cv2.COLORMAP_JET)
# 원본 이미지와 마스트를 적당히 합쳐봅니다
# 0.6과 0.4는 두 이미지를 섞는 비율입니다.
img_show = cv2.addWeighted(img_show, 0.6, color_mask, 0.4, 0.0)
plt.imshow(cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB))
plt.show()
배경 흐리게 하기
blur()함수 사용
# (13,13)은 blurring kernel size를 뜻합니다
# 다양하게 바꿔보세요
img_orig_blur = cv2.blur(img_orig, (100,100)) # 커널 사이즈가 커질수록 blur가 더욱 진하게 바뀜
plt.imshow(cv2.cvtColor(img_orig_blur, cv2.COLOR_BGR2RGB))
plt.show()
세그멘테이션 마스크를 이용해서 배경만 추출
img_mask_color = cv2.cvtColor(img_mask, cv2.COLOR_GRAY2BGR)
img_bg_mask = cv2.bitwise_not(img_mask_color)
img_bg_blur = cv2.bitwise_and(img_orig_blur, img_bg_mask)
plt.imshow(cv2.cvtColor(img_bg_blur, cv2.COLOR_BGR2RGB))
plt.show()
- bitwise_not(): (배경:0, 사람:255) → (배경:255, 사람:0)
- bitwise_and(): 오리지날 블러 이미지와 bg_mask이미지 합성
흐린 배경과 원본 영상 합성
img_concat = np.where(img_mask_color==255, img_orig, img_bg_blur)
plt.imshow(cv2.cvtColor(img_concat, cv2.COLOR_BGR2RGB))
plt.show()
- 세그멘테이션 마스크가 255인 부분만 원본 이미지 값을 갖고, 아닌 영역은 블러된 이미지 값을 사용
'AIFFEL > exploration' 카테고리의 다른 글
| Exploration 09 (0) | 2022.02.03 |
|---|---|
| Exploration 08 (0) | 2022.01.27 |
| Exploration 06 (0) | 2022.01.20 |
| Exploration 05 (0) | 2022.01.18 |
| Exploration 04 (0) | 2022.01.13 |








